


The Hype Around Big Models and What You Need to Know

Big models have captured your imagination with their ability to process vast amounts of information and deliver remarkable results. These models are reshaping data science, driving advancements in areas like language processing and computer vision. However, the hype surrounding them often leads to exaggerated expectations. You must recognize that while these models have immense potential, they also come with limitations. Understanding their true capabilities helps you separate science from speculation and apply them effectively in real-world scenarios.
Key Takeaways
Big models are great for handling big data and hard tasks. But they don’t work for everything. Know their pros and cons before using them.
Good data is key for big models to work well. Use clean and organized data to get accurate results and insights.
People need to guide big models. They can help a lot but can’t work alone, especially for tough choices about right and wrong.
Keep up with new trends and changes in data science. This helps you use the newest tools and ideas better.
Be realistic when using big models. Set clear goals that match the problem you want to solve.
What Are Big Models in Data Science?
Defining Big Models
Big models represent a significant leap in data science. These models are designed to handle vast datasets and perform complex tasks that traditional approaches cannot manage effectively. They rely on advanced techniques like deep learning neural networks and ensemble methods to deliver accurate and robust predictions. Unlike smaller models, big models excel at processing unstructured data, such as text, images, and videos, making them indispensable in fields like natural language processing and computer vision.
Large Quantitative Models (LQMs) are built to analyze large-scale numerical datasets. They perform intricate calculations, statistical analysis, and optimization tasks, often using custom layers and deep learning techniques to enhance their performance.
How Big Models Differ From Traditional Models
Big models stand apart from traditional models in several key ways. They are designed to tackle more complex problems by breaking them into intermediate steps, improving reliability and interpretability. For example:
Large reasoning models (LRMs) use reinforcement learning to enhance reasoning capabilities, allowing for adjustable computational effort.
Google’s Gemini 2.0 processes multiple modalities and generates intermediate reasoning steps, showcasing a level of sophistication beyond traditional models.
Open-source big models can run on less powerful hardware, making them more accessible and cost-effective compared to traditional models.
These advancements enable big models to handle tasks that traditional models struggle with, such as coding, multi-modal data processing, and high-throughput applications.
Examples of Big Models Transforming Industries
Big models have already made a tangible impact across various industries:
In the hospitality industry, machine learning algorithms like collaborative filtering and deep learning power hotel recommendation systems. These systems boost booking conversions and improve user satisfaction.
IBM’s The Weather Company uses advanced machine learning models to enhance weather forecasting accuracy. This innovation supports critical decision-making in agriculture, disaster response, and other sectors.
These examples highlight how big models are reshaping industries by solving complex problems and delivering actionable insights.
Misconceptions About Big Models and Data Science
"Big Models Can Solve Any Problem"
One of the most common misconceptions about big models is the belief that they can solve any problem. While these models are powerful, they are not magical solutions. Their effectiveness depends on the quality of the data they are trained on and the context in which they are applied. For example, a big model designed for natural language processing may excel at generating text but fail when tasked with predicting stock market trends. Each model has limitations tied to its design and training.
Big models also require clear problem definitions. Without a well-defined objective, even the most advanced algorithms can produce irrelevant or misleading results. You must remember that these tools are only as good as the data and instructions they receive. Treating them as universal problem-solvers can lead to wasted resources and unmet expectations.
Tip: Always start with a clear understanding of the problem you want to solve. This ensures that the model you choose aligns with your goals and delivers meaningful insights.
"Data Scientists Are Just Number Crunchers"
Another myth is the idea that data scientists are just number crunchers. This oversimplifies the true nature of data science and the role of a data scientist. Their work goes far beyond analyzing numbers. They act as architects of insights, transforming raw data into actionable strategies that drive business outcomes.
Data scientists play a pivotal role in innovation. They predict future trends, optimize processes, and ensure ethical AI practices. Their contributions impact industries ranging from healthcare to finance. For instance, they might develop machine learning models to detect diseases early or design algorithms that improve supply chain efficiency. These tasks require creativity, critical thinking, and a deep understanding of both data and the business context.
Data scientists pioneer advancements in AI and machine learning.
They ensure that insights are not only accurate but also actionable.
Their work drives strategic decisions, enabling companies to adapt and evolve.
By viewing data scientists as innovators rather than mere number crunchers, you can better appreciate their role in shaping the future of data science.
"More Data Always Means Better Insights"
It’s easy to assume that more data automatically leads to better insights, but this is another misconception. The quality of the data and the context in which it is used matter far more than the quantity. In fact, relying on large datasets without proper analysis can lead to incorrect conclusions.
Consider a project in Rwanda where researchers aimed to predict cholera outbreaks using mobile phone data. They later discovered that the data actually reflected flooding patterns, not disease outbreaks. This example shows how misinterpreting data can lead to flawed insights, even when the dataset is extensive.
Willy Shih from Harvard Business School highlights another risk: data dredging. This practice involves searching for patterns in large datasets without a clear hypothesis, often resulting in spurious correlations. For instance, you might find a link between ice cream sales and shark attacks, but this connection is meaningless without understanding the underlying factors, like seasonal changes.
Eagle, a prominent researcher, emphasizes that good scientific output requires a clear research framework. Collecting vast amounts of data without a defined question or hypothesis often leads to confusion rather than clarity. You should focus on the relevance and accuracy of your data rather than its sheer volume.
Note: Always prioritize data quality and context over quantity. A smaller, well-curated dataset often provides more reliable insights than a massive, unstructured one.
"Big Models Are Fully Autonomous"
The idea that big models are fully autonomous is one of the most persistent misconceptions in data science. While these models are powerful, they still rely on human oversight and intervention to function effectively. You might think that once a big model is trained, it can operate independently, but this is far from reality.
Big models face significant limitations when it comes to achieving full autonomy. For instance, in manufacturing, the highest levels of feature maturity remain unattainable with current technology. This means that even the most advanced systems cannot handle every scenario without human input. Evaluating the autonomy of these models also presents challenges. Their complexity makes it difficult to assess their capabilities accurately. As a result, many systems still require human intervention to ensure they perform as intended.
Consider the example of autonomous vehicles. These systems rely on big models to process vast amounts of data from sensors and cameras. However, they still struggle with edge cases, such as unusual weather conditions or unexpected road obstacles. In these situations, human drivers often need to take control. This highlights the gap between the promise of full autonomy and the current state of technology.
Another area where big models fall short is ethical decision-making. These models lack the ability to understand context or moral implications. For example, a model used in hiring might inadvertently favor certain groups if the training data contains biases. Without human oversight, such issues can go unnoticed, leading to unfair outcomes. You must recognize that human judgment plays a crucial role in ensuring these systems operate ethically and responsibly.
The misconception of full autonomy can lead to unrealistic expectations. Believing that big models can function without human involvement might result in poorly designed systems or failed projects. To avoid this, you should view these models as tools that augment human capabilities rather than replace them. By combining the strengths of big models with human expertise, you can achieve better results and address the limitations of current technology.
Tip: Always include a plan for human oversight when implementing big models. This ensures that the system remains reliable and adaptable to real-world challenges.
Challenges of Working With Big Models
Data Quality and Its Impact on Model Performance
Data quality plays a critical role in the success of big models. Poor data quality can lead to inaccurate predictions, unreliable results, and wasted resources. You might think that advanced models can overcome these issues, but they rely heavily on clean, well-structured data to perform effectively. For instance, data scientists spend nearly 80% of their time preparing data for machine learning pipelines. This includes cleaning, organizing, and debugging data to address unforeseen data quality issues. Without this effort, even the most sophisticated models fail to deliver meaningful results.
Implementing a robust Data Quality Management System (DQMS) can significantly improve the performance of big models. A DQMS ensures that your data is accurate, consistent, and ready for analysis. This not only enhances the efficiency of data processing but also helps you generate reliable data-driven insights. By prioritizing data quality, you can unlock the full potential of big models and make better decisions in data science projects.
Computational Costs and Resource Constraints
Big models demand substantial computational resources, which can strain your budget and infrastructure. For example, deploying ChatGPT costs approximately $100,000 daily or $3 million monthly. These expenses highlight the high cost of running large-scale AI systems. Additionally, 80-90% of machine learning workloads involve inference processing, which requires significant computational power during deployment. This creates a bottleneck, especially for organizations with limited resources.
Cloud computing has become a popular solution for managing these demands. However, the high demand for inference processing, which accounts for 90% of machine learning activity in the cloud, underscores the need for efficient resource allocation. To mitigate these challenges, you should explore optimization techniques, such as model compression and hardware acceleration. These strategies can reduce costs while maintaining performance, making big models more accessible for practical applications.
Ethical Concerns and Bias in Big Models
Big models often face ethical challenges, particularly when it comes to bias. These models learn from historical data, which may contain biases that reflect societal inequalities. If left unchecked, these biases can lead to unfair outcomes. For example, an AI hiring model might favor certain demographics if the training data lacks diversity. This not only undermines fairness but also damages trust in AI systems.
To address these concerns, you must ensure that your data is diverse and representative. Regular audits and bias detection tools can help identify and mitigate potential issues. Additionally, involving diverse teams in the development process can provide valuable perspectives and reduce the risk of biased outcomes. Ethical considerations should remain a priority in data science, as they directly impact the reliability and acceptance of big models.
Environmental Implications of Training Big Models
Training big models comes with significant environmental costs. These models require immense computational power, which translates into high energy consumption and substantial carbon emissions. As you explore the potential of these models, it’s essential to understand their environmental footprint.
Large-scale models like GPT-3 consume vast amounts of energy during training and inference. For example, GPT-3 generates 552 metric tons of CO2 emissions during training, equivalent to the annual emissions of five cars. Its energy consumption reaches 1287 megawatt-hours (MWh), highlighting the scale of resources involved. BLOOM, another big model, emits 50.5 metric tons of CO2 during training, with each query producing 1.6 grams of CO2. These figures underscore the environmental impact of developing and deploying advanced AI systems.
The environmental implications extend beyond training. Inference, the process of using trained models to generate outputs, accounts for a significant portion of energy usage. For GPT-3, inference consumes 60% of its total energy, contributing to a daily carbon footprint of 50 pounds and an annual footprint of 8.4 tons. These ongoing costs highlight the need for sustainable practices in AI development.
To mitigate these impacts, you can adopt strategies like optimizing model architectures, using energy-efficient hardware, and leveraging renewable energy sources. Prioritizing data efficiency during training also reduces resource consumption. By addressing these challenges, you contribute to a more sustainable future for AI.
Note: The environmental costs of big models are substantial, but thoughtful practices can minimize their impact while maintaining innovation.
The Real-World Impact of Big Models
Success Stories Across Industries
Big models have revolutionized industries by solving complex problems and delivering measurable benefits. Their ability to process vast datasets and uncover actionable insights has led to significant advancements. For example, in finance, these models improve prediction accuracy, reducing customer risk misclassification and saving millions by lowering default rates. In healthcare, they enhance disease prediction accuracy, enabling early intervention and reducing the strain on medical facilities.
The table below highlights the transformative impact of big models across various sectors:

These examples demonstrate how big models drive innovation and efficiency, creating a lasting impact on businesses and society.
Limitations in Specialized Use Cases
Despite their versatility, big models face challenges in specialized applications. For instance, healthcare-specific language models often outperform general-purpose models in medical tasks. Adapting existing models with domain-specific knowledge or retraining them using external databases can significantly improve their performance.
However, these models exhibit sensitivity to instruction variations and information order. Performance can fluctuate between 8% and 50% based on how instructions are optimized. Additionally, even advanced models like GPT-4 struggle with basic arithmetic and instruction-following tests. These limitations highlight the need for careful adaptation and evaluation when applying big models to niche domains.
Large language models (LLMs) show sensitivity to variations in instructions and the order of information presented.
Performance can vary significantly (8% to 50%) based on instruction optimization.
LLMs struggle with interpreting numbers and solving simple arithmetic problems.
Even advanced models like PaLM 2 and GPT-4 perform poorly on instruction-following tests.
Understanding these gaps allows you to make informed decisions about when and how to use big models effectively.
Augmenting Human Expertise With Big Models
Big models excel when paired with human expertise, creating a synergy that enhances outcomes. In education, AI-powered tools improve teaching efficiency and personalize learning experiences. Studies show that effective communication between AI tutors and learners leads to better results. Metrics like task completion time and learning curve improvements highlight the value of this collaboration.
For example, in decision-making scenarios, AI complements human judgment by analyzing large datasets quickly and accurately. This partnership often results in better outcomes than either humans or AI could achieve independently. By leveraging big models as tools to augment your expertise, you can unlock new possibilities and drive meaningful progress.
Balancing Innovation With Practicality
Balancing innovation with practicality ensures that big models deliver real value without overwhelming resources or disrupting operations. While innovation drives progress, practical application ensures that advancements align with business goals and constraints.
A prominent example comes from a leading bank that transitioned to cloud technology. By adopting a hybrid cloud model, the bank enhanced customer service and operational efficiency while managing costs. This approach allowed them to address challenges like data migration and compliance without disrupting their existing systems. It highlights how you can integrate cutting-edge technology into your framework while maintaining stability.
Businesses often face the temptation to pursue innovation for its own sake. However, aligning advancements with practical needs is essential. Netflix’s 2009 algorithm contest illustrates this point. The winning algorithm was groundbreaking but never implemented due to integration challenges and shifts in the company’s priorities. This case underscores the importance of ensuring that innovation fits within your operational and strategic context.
Economic considerations also play a role in balancing innovation. According to IDC’s Future Enterprise Resiliency and Spending Survey, most IT leaders plan to maintain or increase technology budgets in 2024. This reflects a commitment to innovation while staying mindful of financial realities. You can adopt a similar approach by prioritizing investments that offer measurable returns and align with your long-term goals.
To achieve this balance, focus on scalable solutions that address immediate needs while leaving room for future growth. Evaluate whether a new technology integrates seamlessly with your existing systems. By combining innovation with practicality, you can maximize the impact of big models and ensure sustainable progress.
Tip: Always assess whether a new solution aligns with your business objectives and operational capabilities before implementation.
Navigating the Hype Around Big Models
Setting Realistic Expectations
When working with big models in data science projects, setting realistic expectations is crucial. These models are powerful, but they are not a one-size-fits-all solution. To ensure success, you need to approach their implementation with a clear understanding of their capabilities and limitations.
Here are some guidelines to help you set achievable goals:
Define measurable and achievable goals. These goals should directly address the identified problem.
Consider ethical implications. Pay attention to privacy, transparency, discrimination, equity, and fairness.
For example, if you plan to use a big model for customer sentiment analysis, start by identifying the specific insights you want to gain. Define metrics like precision and recall to measure the model’s performance. By doing so, you can avoid overestimating what the model can achieve and focus on delivering meaningful results.
Tip: Always align your expectations with the problem you aim to solve. This approach ensures that your efforts lead to actionable outcomes rather than unmet promises.
Building Foundational Data Science Skills
To work effectively with big models, you need strong foundational skills in data science. These skills enable you to bridge the gap between raw data and strategic decision-making, ensuring that your projects deliver value.
Key metrics that indicate essential skills include:
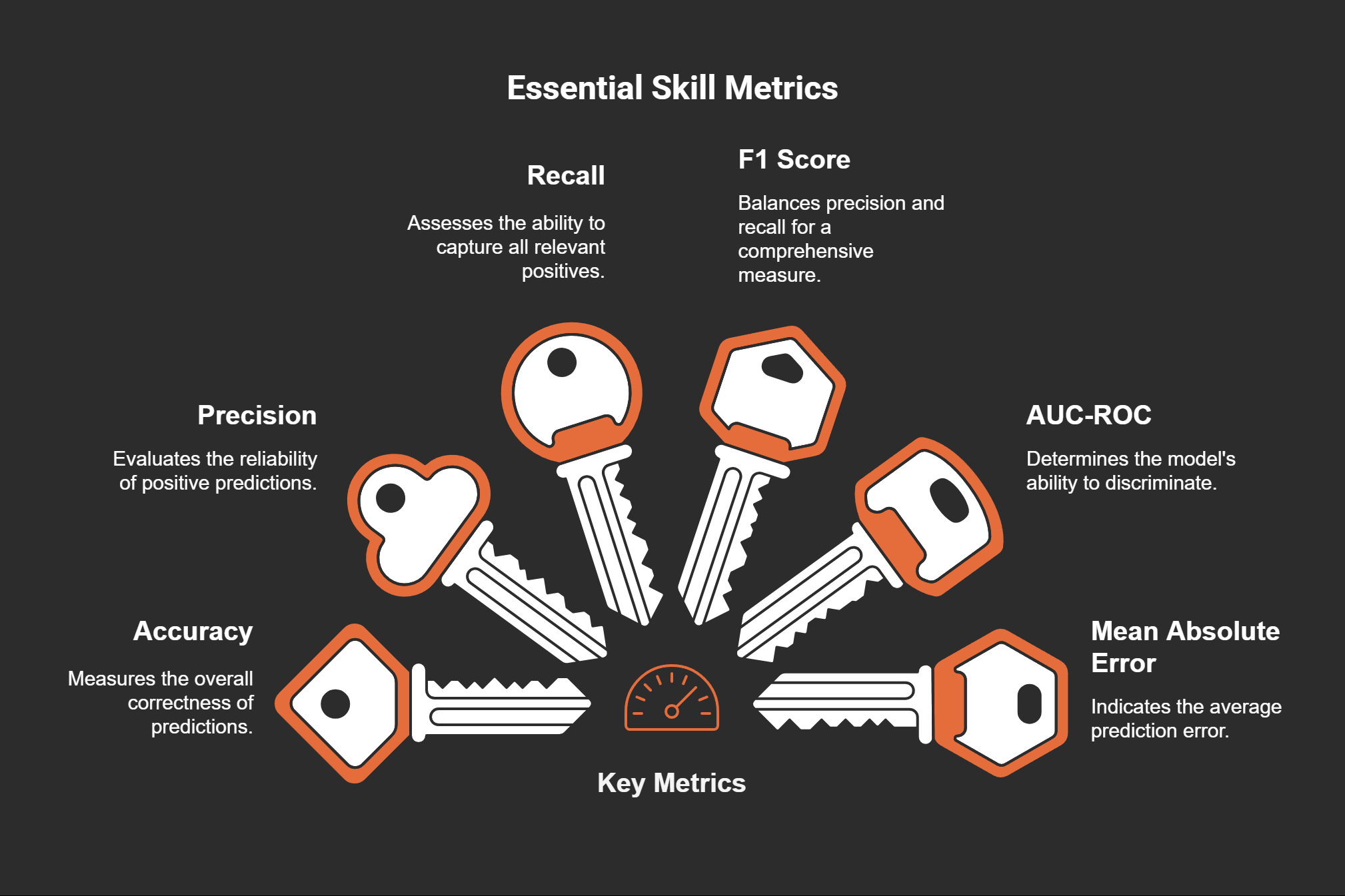
Mastering these metrics helps you evaluate model performance and make informed decisions. Additionally, proficiency in tools like Python is essential for implementing and fine-tuning big models. Python’s versatility and extensive libraries make it a go-to language for data science roles.
As a data scientist, you also need experience in data preprocessing, feature engineering, and model evaluation. These skills ensure that your models are built on a solid foundation, increasing their reliability and effectiveness.
Note: Building foundational skills takes time and practice. Focus on mastering the basics before diving into advanced techniques.
Evaluating When to Use Big Models
Big models are not always the best choice for every data science project. Evaluating their effectiveness requires a careful assessment of the problem, available resources, and expected outcomes.
Different application scenarios call for specific metrics to measure success:
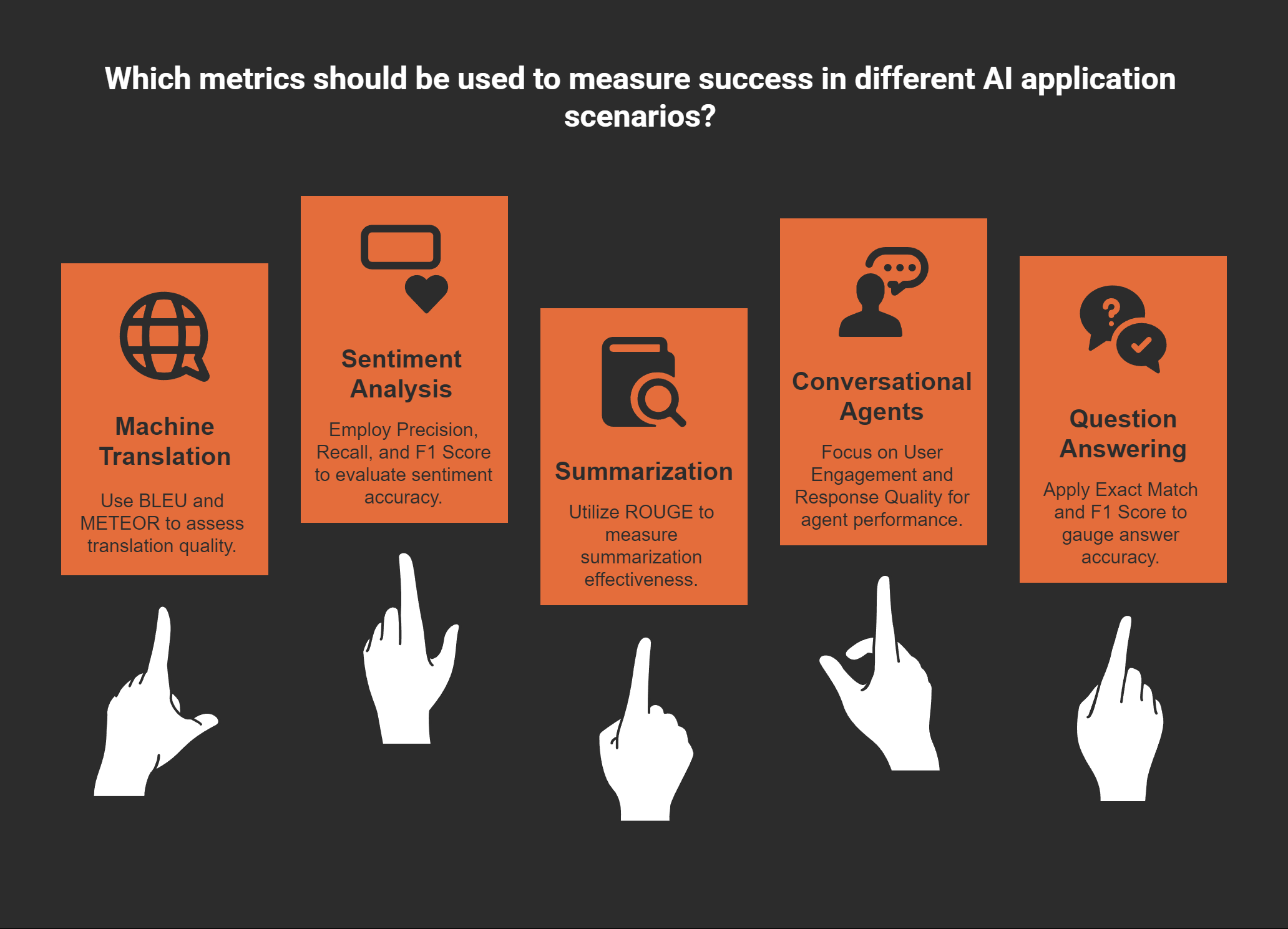
For instance, if you are developing a conversational agent, metrics like user engagement and response quality can help you gauge its effectiveness. On the other hand, for machine translation, BLEU and METEOR scores provide insights into the model’s accuracy.
You should also consider the computational costs and resource constraints. Big models often require significant infrastructure, which may not be feasible for smaller organizations. In such cases, simpler models or hybrid approaches might offer a more practical solution.
Tip: Evaluate the problem’s complexity and the resources at your disposal before deciding to use a big model. This ensures that your choice aligns with your project’s goals and constraints.
Staying Updated on Industry Trends
Staying informed about industry trends is essential for anyone working with big models. The field of data science evolves rapidly, and new developments can impact how you approach projects and solve problems. By keeping up with the latest advancements, you ensure your skills remain relevant and your strategies stay effective.
Why Staying Updated Matters
The pace of innovation in data science means that yesterday’s best practices may no longer apply today. New algorithms, tools, and techniques emerge frequently, offering opportunities to improve efficiency and accuracy. For example, recent breakthroughs in model optimization have reduced computational costs, making big models more accessible. If you miss these updates, you risk falling behind competitors who adopt them early.
Staying updated also helps you anticipate challenges. As big models grow more complex, ethical concerns like bias and environmental impact become more pressing. By following industry discussions, you gain insights into how others address these issues and apply similar strategies to your projects.
Practical Ways to Stay Informed
You can use several methods to stay current with industry trends. Here are some effective approaches:
Follow Reputable Publications
Subscribe to journals, blogs, and newsletters focused on data science. Sources like MIT Technology Review and Towards Data Science often cover emerging trends and case studies. These platforms provide actionable insights that you can apply directly to your work.Join Online Communities
Participate in forums and social media groups where data scientists share experiences and discuss new developments. Platforms like Reddit’s r/datascience and LinkedIn groups offer valuable perspectives from professionals worldwide.Attend Conferences and Webinars
Industry events provide opportunities to learn from experts and network with peers. Conferences like NeurIPS and webinars hosted by organizations like SAS often showcase cutting-edge research and practical applications.Take Online Courses
Platforms like Coursera and edX offer courses on the latest tools and techniques in data science. These courses help you deepen your understanding and stay ahead in your field.Experiment with New Tools
Hands-on experience is one of the best ways to learn. Explore new software, frameworks, and libraries to understand their capabilities. For instance, experimenting with open-source big models can reveal their strengths and limitations.
Leveraging Trends for Success
Once you identify emerging trends, consider how they align with your goals. For example, if a new technique improves data preprocessing, evaluate whether it fits your workflow. Adopting relevant innovations ensures your projects benefit from the latest advancements without unnecessary disruptions.
You should also share your knowledge with colleagues. Discussing trends within your team fosters collaboration and helps everyone stay informed. This collective approach strengthens your organization’s ability to adapt and innovate.
Tip: Make staying updated a habit. Dedicate time each week to reading articles, joining discussions, or experimenting with tools. Consistency ensures you remain informed and prepared for changes in the industry.
Big models offer immense power, but they are not a universal solution. You must understand their strengths and weaknesses to use them effectively. Their capabilities shine when paired with clear objectives and high-quality data. However, relying solely on these models can lead to unrealistic expectations. A balanced approach, grounded in the fundamentals of data science, ensures long-term success. By combining human expertise with advanced tools, you can unlock meaningful insights and drive innovation in science and beyond.
FAQ
What makes big models different from traditional models?
Big models process vast amounts of data and handle complex tasks like natural language processing and computer vision. They use advanced techniques, such as deep learning, to deliver results that traditional models cannot achieve.
Are big models suitable for small businesses?
Big models can benefit small businesses if the data infrastructure supports them. Open-source options and cloud-based solutions make these models more accessible, reducing costs and resource constraints.
How do you ensure ethical use of big models?
You must audit training data regularly and involve diverse teams during development. Bias detection tools help identify issues, ensuring fairness and ethical outcomes.
Can big models work without human intervention?
Big models require human oversight for ethical decision-making and handling edge cases. They augment human expertise but cannot operate independently in complex scenarios.
What are the environmental impacts of big models?
Training big models consumes significant energy, leading to carbon emissions. You can mitigate this by optimizing architectures, using energy-efficient hardware, and leveraging renewable energy sources.